Research Radar is a working prototype. The goal is straightforward: ranked lists of MIR and audio ML papers where you can see why each result landed where it did. You can move from the main feed into a paper, check the evaluation against simpler sorts, and follow trends in the current dataset without losing the reasoning behind the order. The live app runs separately from this case study; the bridge feature is visible as a separate experimental view and is kept out of the main recommendation flow for now.
Research Radar centers on one workflow: inspect ranked recommendations, open a paper dossier, compare against baselines, and read trends in corpus context. The core value is making the ranking signals visible.
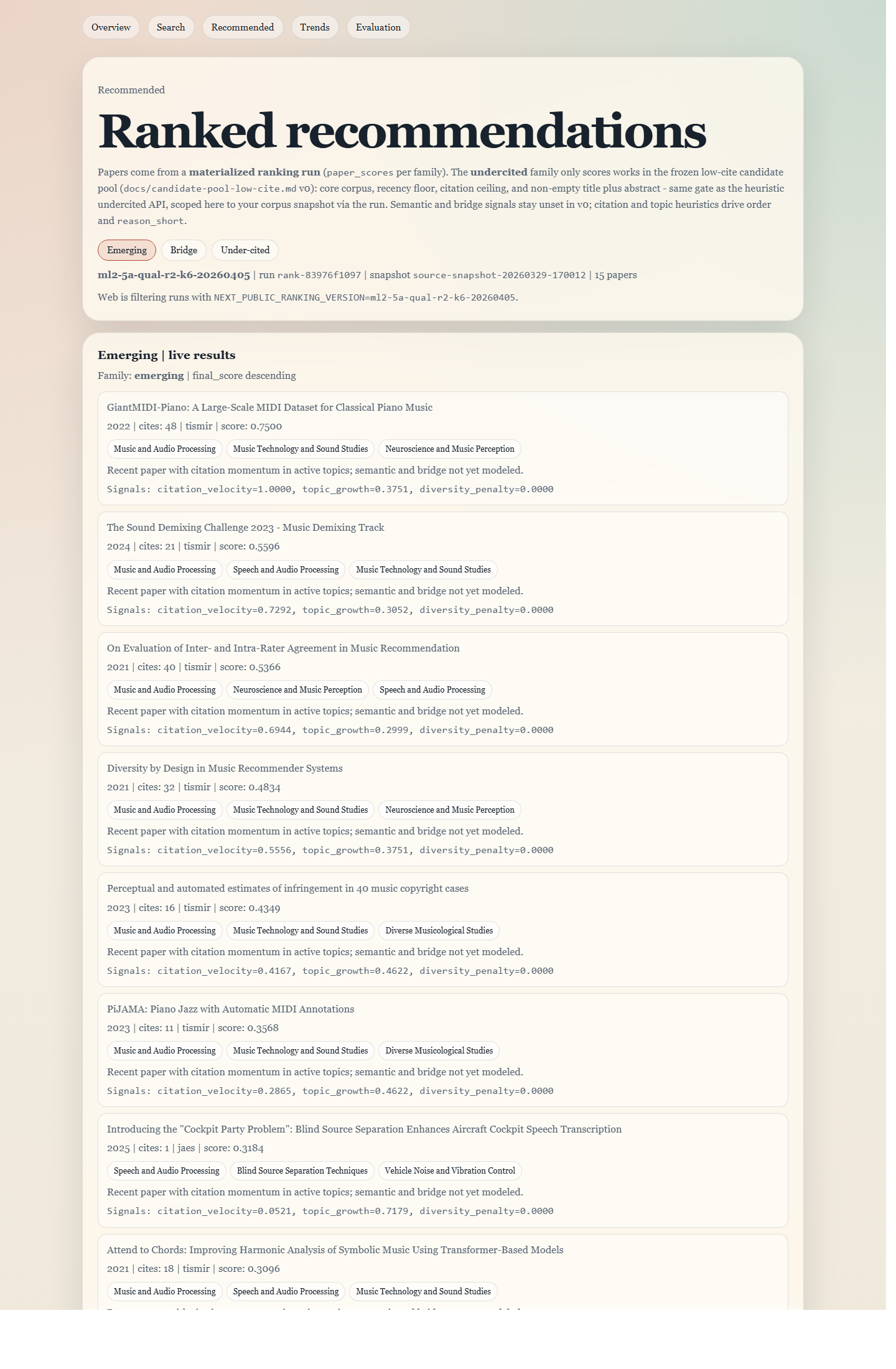
Ranked recommendations
Two main feeds: emerging papers and undercited papers. Each list is precomputed and every card includes enough context to show why that paper ranked where it did.
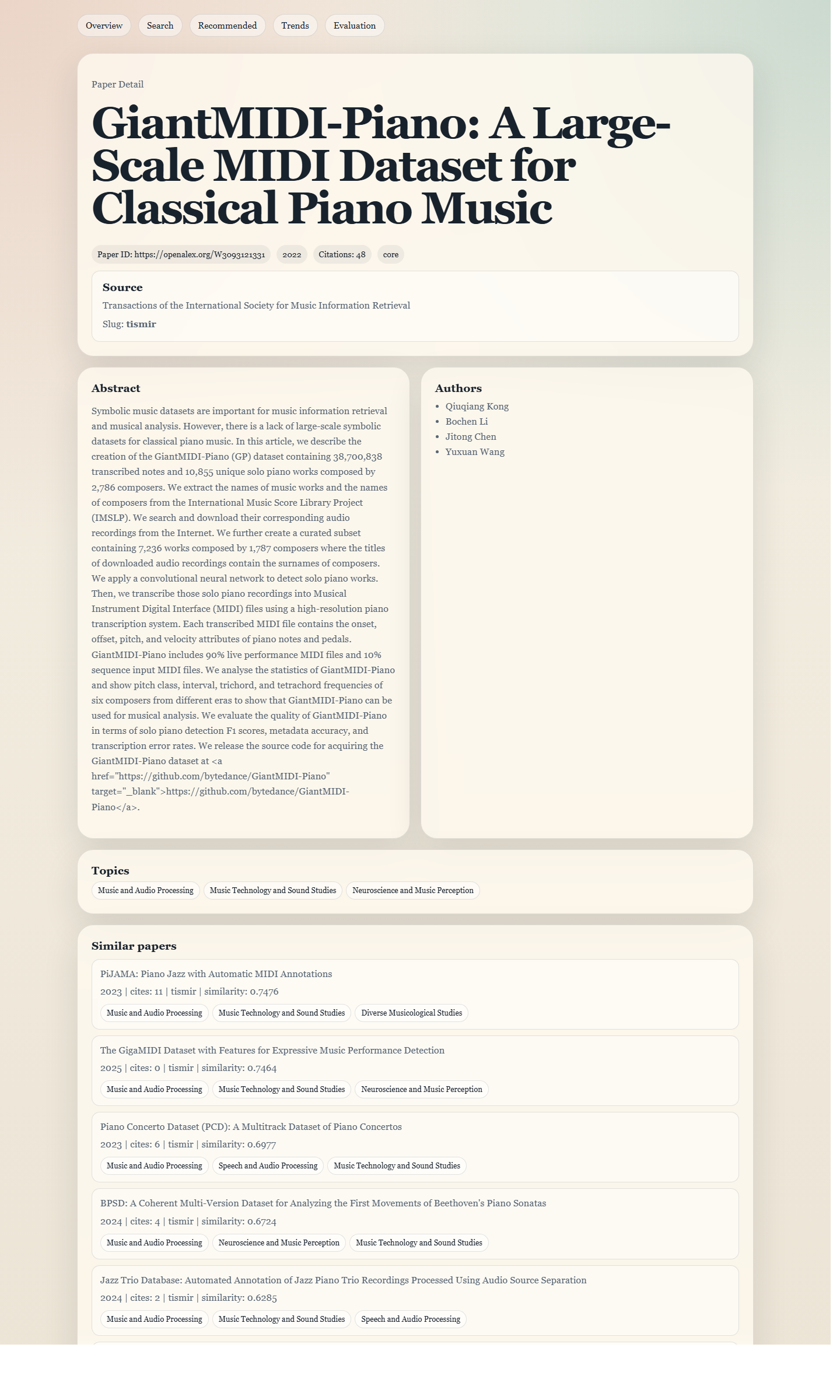
Paper detail with similar papers
Each paper page shows metadata plus a related-papers section, so someone can move from one useful paper to the next without starting over from search every time.
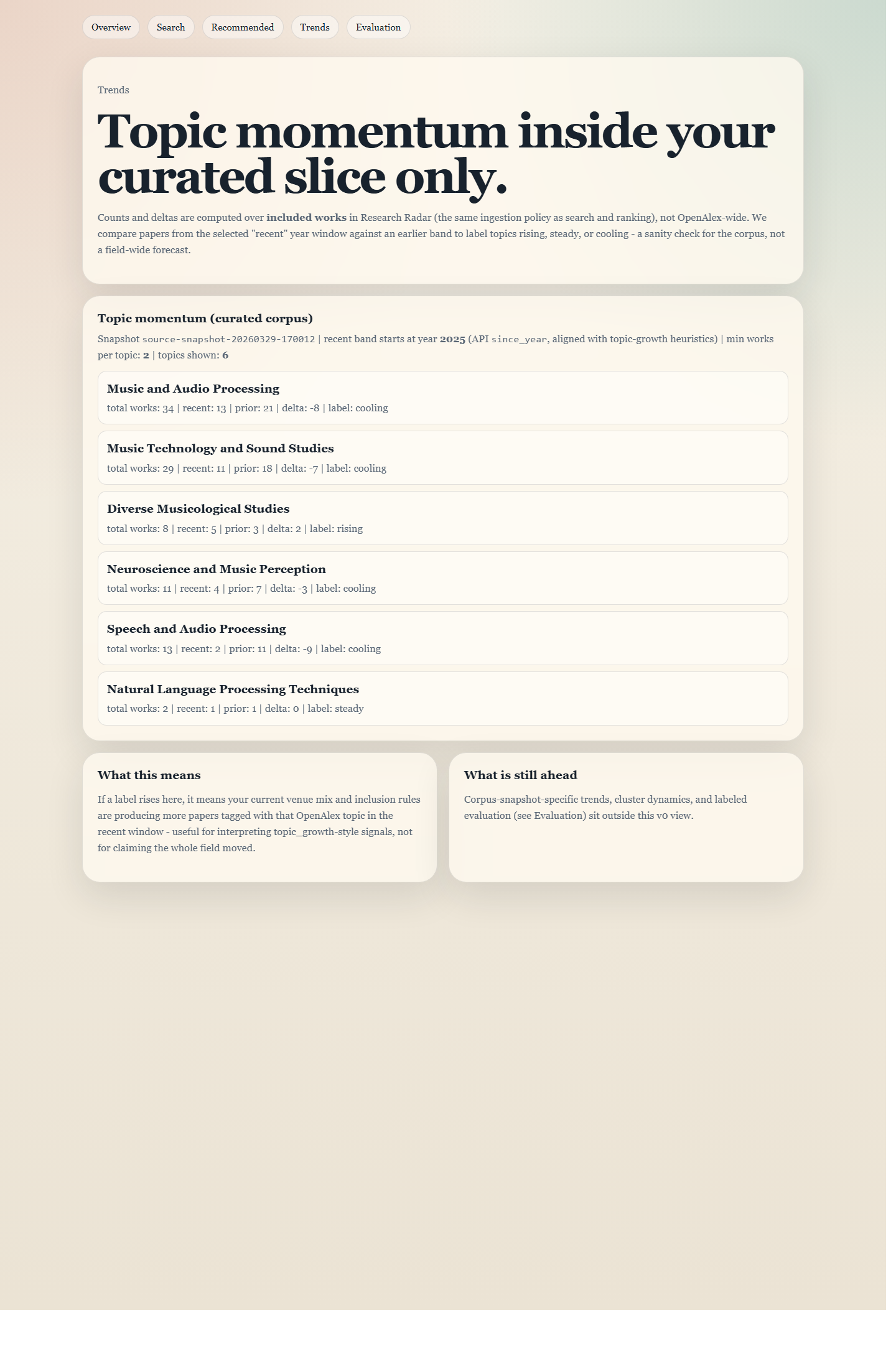
Trends in the current dataset
The trends page shows which topics are gaining traction inside the papers the ranker is working with. Useful context for recurring topics in the feeds.
Evaluation and comparison
The evaluation page compares the ranking against simpler baselines like citation count and recency so you can sanity-check behavior against scores everyone already understands.
Engineering choices
Recommendations should answer "why is this here?"
Each ranked list stores the signal mix that produced it alongside the results. When the ranking code changes and something moves, you can check what actually shifted instead of guessing. It also gives anyone reviewing the work something concrete to push back on.
Splitting the site from the prototype is intentional
This page is the case study, while the prototype runs as its own app. Under the hood there is a Next.js frontend, a FastAPI backend, Postgres with pgvector for storage and similarity search, and Python jobs for ingest, ranking, and clustering. Keeping those pieces separate makes it easier to update the ranking workflow without turning every change into a full-site deploy.
Experimental ideas stay visible and clearly labelled
Bridge is the main example: the signal is measured and shown in the UI, but it is kept out of the final score until the feature is strong enough to earn that role. I'd rather show the work in progress than hide it.
Scope and evaluation boundaries
Current corpus scope is intentionally narrow. The deployed corpus is curated around the currently wired bootstrap sources, and it should not be read as a comprehensive index of audio-ML literature.
Evaluation here is proxy-only: citation/date baselines, topic-mix and recency checks, plus distribution-level comparisons. There is not yet a human-labeled relevance benchmark.
Visual walkthrough
Most paper tools give you a sorted list and no explanation of why anything landed where it did. I built this partly to fix that and partly to understand what it actually takes to build something like this end to end. The way I use it: open the emerging or undercited feed, read the signal note on each card before trusting the order, click into a paper if it looks worth following, then check the evaluation page to see whether the ranking makes sense against simpler sorts like citation count or date.
This is the main list. Each card shows a paper and a short breakdown of what pushed it up in the ranking for this snapshot. You don't have to take the order on faith.
What to look at
Pick any card and read the signal block below the title. That's the system's reasoning for that result.
The feed is either emerging (newer papers gaining traction in this set) or undercited (papers that look underappreciated relative to their signals).
What you can take from this: The signal mix is visible enough to explain each result and compare runs when the code changes.
Boundary: The corpus is curated and narrower than the field. Objective best-paper claims are out of scope.
Click any card from the feed and you land here. You get the paper's full details, where it sat in the ranked list, and a set of similar papers so you can keep exploring without starting over.
What to look at
Venue, year, citation count, and topic tags are all in one place.
The similar papers section finds nearby results by content. Useful when one paper looks relevant and you want to see what else is around it.
What you can take from this: You can move from a ranked result to a full paper view and keep moving through related work without losing your place.
Boundary: Similar papers are matched by content similarity. Treat them as navigation aids, not quality judgments.
This is where I check whether the ranking is actually doing something useful. It puts the system's output next to the most obvious alternatives: sort by citation count, sort by date. If the ranking is adding value, you should be able to see it here.
What to look at
Compare which papers appear in the ranked list versus what you'd get from a simple sort by citations or recency.
Look at the overall shape, not just individual rows. Does the ranked list feel meaningfully different from the simple sorts?
What you can take from this: A quick sanity check that the ranking is doing something beyond what a spreadsheet sort would give you.
Boundary: This compares against simple baselines. It is a useful starting point before a formal relevance benchmark exists.
What you can verify without special access: repository history, linked tests, roadmap notes, and the screenshot baseline shown in the walkthrough above. Internal hosting details are intentionally omitted; the live prototype uses the stable radar.mmaitland.dev subdomain.
Stable now
The two main feeds (emerging and undercited) are working and show you why each paper ranked where it did. Bridge is visible as a separate experimental view.
Paper detail, trends, and evaluation are all working parts of the prototype.
The most useful thing it does right now: you can see the ranking logic, compare runs, and check it against simpler sorts.
What is still experimental
In the referenced stable run, bridge weight is zero, so final_score does not use the bridge signal.
I tested weighted variations; with the current signals the deck order barely moved, so the next lever is the bridge features themselves.
The next step is likely better bridge signals and tighter filtering before touching the scalar weights again.
Boundaries
General semantic relevance is not treated as a default quality score. Some pinned emerging runs use embedding fit as one ranking feature, and the live UI labels when that feature is used.
Bridge is currently presented as an experiment, separate from the main recommendation path.
The corpus is still curated and narrower than the long-term vision.
Tech stack
The interface is built in Next.js, the API is built in FastAPI, and the data lives in Postgres with pgvector. A separate Python pipeline handles ingest, cleanup, embeddings, ranking, and clustering experiments behind the scenes.
Building the explanation layer early turned out to matter more than I expected. Once each run stored why it ranked the way it did, comparing versions became straightforward instead of guesswork. Keeping bridge visible as a separate experimental view also helped: the core flow stayed focused, and I could work on the experimental side without it polluting the main results. The evaluation page earned its place too. I kept expecting a single summary score to be enough, and it never was. Seeing the full comparison grid against simple sorts was always more honest.
The strongest stable claim today is that the prototype makes its ranking behavior visible and understandable over a curated set of MIR and audio ML papers.
Known limits: Bridge is an experimental view separate from the main recommender; semantic similarity only appears in runs where the UI labels it; the corpus is still narrower than the long-term plan.
Leave a question or comment
No questions or comments yet. Sign in with GitHub to leave the first one.